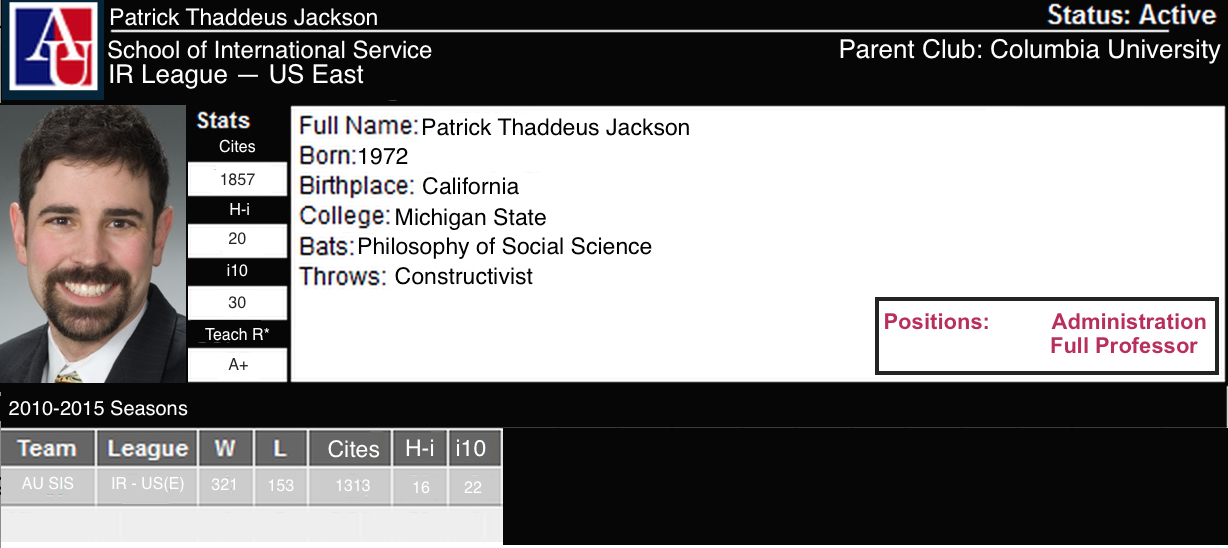
PTJ’s Essential Player Statistics
This is a guest post by both Nexon and Patrick Thaddeus Jackson. Standard disclaimers apply.
Cullen Hendrix’s guest post is a must read for anyone interested in citation metrics and international-relations scholarship. Among other things, Hendrix provides critical benchmark data for those interested in assessing performance using Google Scholar.
We love the post, but we worry about an issue that it raises. Hendrix opens with a powerful analogy: sabermetrics is to baseball as the h-index is to academia. We can build better international-relations departments. With science!
The main argument in favor of the h-index is that it predicts academic productivity. What’s the h-index?
A scientist has index h if h of his/her Np papers have at least h citations each, and the other (Np − h) papers have no more than h citations each.
Google scholar includes books and anything else it crawls. So if someone has an h-index of 18, that means that they’ve ‘published’ 18 pieces with at least 18 citations.
What does the h-index do, exactly? It supposedly predicts both Np (the number of papers that a scholar is likely to publish over my career) and Nc (the number of citations a scholar will likely accrue). Or, at least, it does so better than alternative measures, such as a total count of publications, the mean number of citations, or various other ways of manipulating publication and citation data.
Thus, armed with h-indexes and other predictive measures, the field can objectively rank individuals and departments. Meanwhile, departments themselves can “field” better international-relations and political-science “teams.”

The University of Chicago Plays a Pokéball
But how, exactly? Despite Dan’s best efforts, we have yet to convince either the American Political Science Association (APSA) or the International Studies Association (ISA) to transform themselves into Pokémon-style tournaments in which departments battle it out for ultimate dominance based on Google Scholar statistics, type, and abilities of their members.

Nexon is a Mid-Tier Pokémon
And herein lies the basic difference between, on the one hand, academia, and, on the other hand, competitive sports and other games. The constitutive rules of the latter serve to sort winners from losers (note exception that proves the rule). In academia, the terminology of sports and games operates, at best, as metaphor.
Let’s return to the analogy with sabermetrics. Baseball, after all, is actually a game. It has pretty clearly defined rules and a formal organization tasked with upholding those rules. The net result: when one steps into a ballpark or puts on a pair of cleats and picks up a bat and ball, there exists little ambiguity about the point of the exercise. Playing baseball means to try to score more points than one’s opponents. This leads to winning the game. Such certainty about constitutive rules makes it possible to ask questions about which activities make the most contribution to that end. The rules define acceptable contributions, such as hitting the ball in such a way that fielders cannot catch it. We can both quantify those rules and also relate to the ultimate outcome: scoring sufficient runs to win the game.
Sabermetrics, after all, amount to an intervention into a game that already enjoyed existing measures of player performance and productivity. It sought to replace those statistics, like “runs batted in” and “hits with runners in scoring position,” with measures like “on base percentage + slugging percentage.” Sabermetricians argued that their new measures provided more accurate ways of assessing a player’s contribution to the goal of the game.
Eventually this leads us to notions like “win share” as a comprehensive alternative to traditional measure of player performance. But the critical point here is that while measurements changed, the overall goal did not; the rules of the game remained the same; the point of playing the game—to score more runs than the other team, and thus win the game —continued unchanged.
Back to the h-index. Even if a scholar’s h-index reliably predicts publications and citations over a career, it remains unclear that this provides a reliable indicator of that scholar’s contribution to the overall point of the academic exercise. Does the scholar who amasses the most citations over a career “win” academia (“she who dies with the most citations wins”)? Does a department composed of scholars with high h-index numbers “win” higher education? What does “winning” even mean?
This creates two problems: one conceptual and one practical.
The conceptual problem, as the discussion Hendrix kicks off already demonstrates, is that citations remain, at best, a proxy for impact. So even if one argued that a major part of the academic vocation involved generating knowledge, it is unclear that citations provide a good way to measure that. Samuel Huntington’s The Clash of Civilizations gets cited a lot. But how many of us would regard that as an enduring contribution to knowledge? Ken Waltz’s Theory of International Politics gets cited a lot, but how many of those citations are by people highly critical of Waltz’s whole approach?
One might argue that this renders both works “impactful.” After all, if everyone feels it necessary to engage with them, then they matter, right? Or one might argue that this makes both books contribute highly to ‘knowledge production’ in their role as foils. But these both suggest a procedural view of ‘knowledge production’: knowledge production resides in the process of being cited, not in whether the work itself makes an independent contribution to knowledge. And it raises difficult counterfactual questions: would the effort spent on debating The Clash of Civilizations have been better spent arguing about other things? Would scholarship have looked better, or worse, if we hadn’t been debating Theory of International Politics?
We might disagree on these questions, but such debate pushes us back into the realm of quote-unquote subjective estimations. They highlight that whatever citation counts measure, it is perhaps only tangentially related to knowledge-production. And being cited constitutes only one part of an academic vocation in any case; what about the “impact” a teacher exercises by helping her students learn how to think critically about international affairs, even if those students don’t cite her published work because they don’t go into academia? It is not obvious who ‘wins’ in that case, the highly cited scholar or the inspiring teacher.
This leads to the practical issue, which we might call the performativity problem inherent to these kinds of efforts to systematically assess impact and productivity. Once we establish a certain statistic as a metric for productivity, we change the game and give the players—which means: us and our colleagues—a new set of goals to aim for and rules to adhere to. The effort to measure scholarly productivity thus becomes a self-fulfilling prophecy, as we literally write and talk a revised set of scholarly norms into existence.
Unlike in baseball, where a new statistic once proposed has to be assessed for its actual contribution to the commonly-understood point of the game, productivity metrics in academia constitute novel goals and shape subsequent scholarly efforts in accord with them. Witness academic journals striving to increase their impact factors, or UK departments striving to do better in the REF/RAE process , or departments engaging in efforts to increase their ranking in the TRIP survey. This is nothing new, of course. An entire industry dedicates itself to helping students improve their scores on various standardized tests. Consultants and evaluators take up the same role with respect to academic institutions and departments. The means becomes an end in itself, and the measurement becomes a goal.
Now, this problem is less pronounced in professional baseball, precisely because players’ efforts to increase his OPS actually do contribute to their team’s proclivity to score runs. Do our efforts to publish pieces more likely to be cited actually contribute to knowledge, or to the education of our students and the broader public? Unless we are absolutely sure that they do, we should be cautious in our claims about any metric for scholarly productivity.
Indeed, consider a well-rehearsed process that obtains when creating metrics for activities that involve difficult-to-measure and difficult-to-define outputs: given a choice between “intangibles” and “numbers,” people almost always choose numbers because they create the veneer of objectivity—of unbiased—measures. Of course, what undergirds those numbers often entails a host of less than “unbiased” forces. When it comes to citations and publication, such forces include so-called citation cartels and other aspects of disciplinary politics. Such factors are inevitable, of course, but metrics such as the h-index don’t really substitute for them so much as risk hiding their operation.
Again, this would prove less of a concern in the absence of performativity dynamics. But these dynamics mean that the more that rely on them, the more they’ll function to allocate academic status and prestige in ways that render them real. If we use productivity measures to allocate funding, for example, then more ‘productive’ scholars and departments will enjoy more resources, and thus prove better able, all things being equal, to succeed at those measures.
Before we know it, we’ve transformed academia into something that looks a lot like baseball.
But academia isn’t baseball. And it shouldn’t be.

Daniel H. Nexon is a Professor at Georgetown University, with a joint appointment in the Department of Government and the School of Foreign Service. His academic work focuses on international-relations theory, power politics, empires and hegemony, and international order. He has also written on the relationship between popular culture and world politics.
He has held fellowships at Stanford University's Center for International Security and Cooperation and at the Ohio State University's Mershon Center for International Studies. During 2009-2010 he worked in the U.S. Department of Defense as a Council on Foreign Relations International Affairs Fellow. He was the lead editor of International Studies Quarterly from 2014-2018.
He is the author of The Struggle for Power in Early Modern Europe: Religious Conflict, Dynastic Empires, and International Change (Princeton University Press, 2009), which won the International Security Studies Section (ISSS) Best Book Award for 2010, and co-author of Exit from Hegemony: The Unraveling of the American Global Order (Oxford University Press, 2020). His articles have appeared in a lot of places. He is the founder of the The Duck of Minerva, and also blogs at Lawyers, Guns and Money.
- Dan Nexonhttps://www.duckofminerva.com/author/dhnexon

- Dan Nexonhttps://www.duckofminerva.com/author/dhnexon

- Dan Nexonhttps://www.duckofminerva.com/author/dhnexon
- Dan Nexonhttps://www.duckofminerva.com/author/dhnexon
- Dan Nexonhttps://www.duckofminerva.com/author/dhnexon
- Dan Nexonhttps://www.duckofminerva.com/author/dhnexon


Dan, Patrick, this is a great post. Jarrod and I have something coming that deals with this issue. It should be ready for DoM by late August. One thing that I would add to your critique is that these metrics are often viewed through the lens of regional concerns. A highly cited article in the US may have little purchase in Europe, and vice versa. This regionalism can severely complicate ‘objective metrics’ of an article’s value.
In other words, is there a difference in the value of an article that has 200 hits on Google Scholar but all largely confined to the United States, versus an article with 100 hits distributed across a dozen different countries? How do citation metrics capture the importance of an article appealing beyond borders?
I think this is making my head explode… It seems vaguely related to my desire for the creation of a journal “value added” measure that would provide estimations for how much of a ‘boost’ to Nc an article gets for appearing in a particular journal, but sliced-and-diced by geography.
One more thought about this in terms of the recent DP debate in ISQ. Assume Poznansky’s and Barkawi’s pieces both receive a high number of citations (as I suspect they will, they look good). What if the former is cited predominantly in the US while the latter is cited more broadly? Would that support Barkawi’s view of DP theory as a distinctly American project? What if the converse is true, does that mean DP theory is actually an objective social-scientific fact?
It’d be interesting to know how this shakes out five years from now.
In order to come up with a metric (objective or not), we’d have to first agree on the purpose of academia – or at least IR academia. Good luck with coming up with consensus on that. And maybe it’s good that we don’t have consensus.
I would love to see a metric along the lines of “genuinely new ideas” – and keeping in mind the Waltz and Huntington, we’d probably need to be more specific, e.g., “genuinely new and GOOD ideas,” seeing as Huntington was clearly visited by the Bad Idea Fairy multiple times later in his career. I once asked Richard Ashley why he didn’t publish more; he replied that he liked to wait until he had a new idea. Such a metric would encourage more thinking and less incontinence of the keyboard.
Also, where can I get a card like Patrick’s? [And how do you calculate your institution’s W-L record, anyway?]
If we could calculate the W-L, PTJ could have a real card ;-).
I used preview to amateurishly and laboriously “photoshop” something I found on the web.
Wouldn’t Ashley do pretty well in a Moneyball system, though? :-)
Alex, I didn’t get a chance to read this before I wrote my post – but I think the question of purpose is exactly my struggle with this debate … https://relationsinternational.com/why-i-dont-give-a-shit-about-my-h-index/
I agree that it’s not a very good analogy: a big part of using metrics in baseball was to find *undervalued* qualities that indicate strong performance, and then exploit those market inefficiencies to out-perform richer peers. (I think hiring departments could employ this strategy if they wanted to do so, but very few do.) I don’t see citation counts (RBIs?) as particularly undervalued, and something like an h-index is very similar to paleo baseball stats like batting average.
Academia might not be baseball but it certainly resembles a game in some key ways: strategic behavior is certainly rewarded.
That said, I think it definitely is worth looking for interesting patterns in these and other data. In one important sense I think the analogue to Moneyball is fine: in Moneyball, senior scouts were missing important characteristics of players by relying only on subjective criteria; it seems entirely possible — almost certain in at least some cases — that scholars writing tenure letters or whatever might do the same thing.
If developed and deployed correctly citation-based metrics could help reduce some of that subjectivity, much of which is as biased as citation-based metrics themselves. Does that mean they can, or should, entirely replace subjective assessments? Of course not. And the argument that the “Moneyball” revolution did so in baseball is completely overblown. All successful teams — indeed, all teams full stop — use both.
I read Hendrix’s post as simply saying that since these data exist we should try to make some good use out of them. Which strikes me as unobjectionable. Why would we want to ignore information that is readily at our disposal? Yet, that is the only actionable conclusion that I can discern from this post.
So I don’t understand the objection from a “what’s the alternative and is it any better” point of view. And I don’t understand it coming as it does from two scholars who are some of the most dedicated in our field to public outreach, fostering scholarly debate, and increasing public access to scholarly works. If successful, these actions are likely to… boost citation counts (among other, less measurable, things)!
Maybe the better analogy would have been to the earliest days of baseball, when “batting average” first replaced “old Lefty McGillicutty is the finest batsmen to every grace the friendly confines of Shibe Park, I tell ye…”
And yeah, baseball had been cruising along for quite some time before Shibe Park was built…I was going for a Monty Burns reference.
I also thought this was a fantastic post and wanted to offer a response to W. K. Winecoff’s last question. As I understand it, you are saying that there are two alternatives, use the data or ignore it, and ignoring it is just silly because more information is always better. I’d like to put the case for ignoring it, mainly using the points made in the original post. I’ll leave aside measurement issues, like what counts as a citation (non-peer-reviewed outlet? blogpost? syllabus?). My main point is that the mere existence of the measure will have effects and that qualifiers like “If developed and deployed correctly” are reminiscent of debates over communism in theory vs communism in practice. (I’d also mention that a concern with “productivity” rather than “impact” reflects a perhaps peculiarly American moralistic obsession with working all the time.)
One argument in favor of ignoring the data is that an easily accessible number will lead to the crowding out of other forms of evaluation, leading to people not doing things that won’t contribute to increasing that number. This is part of the performativity problem. So if there is anything else that we think scholars should be doing that is not captured in the measure, having the measure at all means less of that thing. Various teaching and outreach activities are the obvious candidates. Another argument is that there will be a way that the number is calculated and that way will not perfectly incentivize the kind of behavior that we want to incentivize and so promote “gaming” of the metric. One example might be spreading work out to the minimum publishable unit. Also, because it is seen as objective (as you say) and so creates the illusion that it is better than some other type of judgment when allocating resources. As Nexon/PTJ point out, we have no good, clearly articulate, reason to think that citation counts are “better” than other types of judgments.
A more fundamental problem is that numbers like the h-index or citation counts are interval-level variables. This means, inter alia, that they are ranked, creating the illusion of a hierarchy where there may be none. Imagine someone working on the behavior of rebel groups in civil war who is working on a topic with lots of other people involved who cite each other a lot but who are all making relatively incremental contributions on each others’ work. Then contrast that with someone studying political coalitions in Botswana who works out exactly the dynamics underlying the last election there. What does it even mean to say that one is more or better than the other? The utility of a metric is that it enables you to say, e.g., Botswana scholar A has more impact than Botswana scholar B. But the mere existence of the measure means that people will use it to create ordinality where there isn’t any, or shouldn’t be any. Some comparisons, perhaps most comparisons between scholarly output are differences of kind, not of number. Again, the mere existence of the measure means that abuse will happen. And so, ignoring it or prohibiting its use, or even getting rid of it, is the preferred option.
“”If developed and deployed correctly” are reminiscent of debates over communism in theory vs communism in practice.”
Are you %^&*ing kidding me? In what way are the two reminiscent of each other? Google Scholar may miss a hit or several here or there, but it’s not going to miss 500 citations nor wrongly add 500. But even if it did, we’d want to know why that was happening so we could contextualize the numbers. Right? Ignoring them adds no value.
Every other point you made can just be made in reverse: relying solely on the impression of Scholar X is no more pure, but judgments over quality and impact are — and, sorry to say, must be — made nevertheless. People are already incentivized to produce work that generates “impact”, which is currently defined in many many different ways. So I’ll stick with my conclusion… why not both? I really don’t see the downside here unless you are just opposed to counting things up as a universal rule.
My intention with the communism debate analogy was to suggest that you could exclude any negative effects of the citation index by saying “well, it is not being deployed correctly”, in the same way that you could say explain failures of really existing socialism by saying that it wasn’t true socialism.
Say a department institutes a rule that you must have an h-index of X or higher in order to get tenure, or get hired in the first place. But because books are undercounted, say, people doing book-type work get fired or don’t get jobs. Well, one might say, that is not a problem of the information, that is a technical issue that if only we tweaked the index properly would not happen. And besides, having a rule like that is not a correct deployment of the information. And yet, regardless, there are practical consequences to the existence of the index given the frailties of human decisionmaking.
But you are missing the point when you refer to Google Scholar miscounting citations. The issue is that citations (even if you could take into account the “quality” of citations) are not the only measure of quality. But if there is an easily accessible number that purports to measure “scholarly goodness”, people and organizations will move towards using that number to the exclusion of everything else, and for purposes that make no sense.
And it is not the case that the only alternative is to do the same thing with “impressions by Scholar X”. Sometimes we should do nothing at all. That is, sometimes there should be no judgment over quality and impact-as-citability. For example, resources could be allocated at random or according to some sort of idea of fairness, like who needs it more.
“Say a department institutes a rule that you must have an h-index of X or higher in order to get tenure, or get hired in the first place.”
No, let’s not say that. It’s never happened, no one is proposing such a rule, and if any college or university ever tried to impose one it would probably violate employment contracts and/or otherwise raise the ire of a whole host of groups, including faculty senates and the AAUP (in the US case). At best this is a slippery slope argument.
As it stands, I think there are many more places where having a book is a prerequisite for tenure than places where it would hurt you via under-counting. And if books truly are undercounted — I’m not sure about that, truthfully; the claim I’ve seen is that things cited *in* books are undercounted, since Google hasn’t scanned every book in the world — they are still almost certainly much more highly-cited than any randomly selected article.
I’ve never said citations measured quality, and neither has anyone else, so no: I’ve not missed the point. As the OP says, sometimes things are cited a lot because they are bad and they provide a useful foil. But since not one single person has yet suggested that we ditch subjective assessments entirely in favor of context-free statistics I don’t really think that’s a problem. If my main piece of research is only being cited so that people can laugh at it that will probably turn up in my external letters.
There are already informal rules about how good an h or how much of an impact one needs to have to get tenure. Departments don’t need to *say* this in order for it to be the case. And it’s not just, or perhaps not even mainly, departments; it’s university-level committees, deans, provosts, and boards of trustees. Context gets lost as you move up the chain; only the number remains.
“Context gets lost as you move up the chain; only the number remains.” … and those employed primarily (solely?) to evaluate, plan, and boost the numbers (this is particularly the case in the UK REF climate). This debate clearly has legs, here’s hoping it has enough to walk as far up the chain as necessary to reach administrators and management professionals who really need to hear it.
I’m heartened that my original post has sparked this much discussion. While opinions will vary as to the utility of metrics-based assessment, I think it’s best to have these discussions in the open. The simple fact is that we make comparisons and implicit judgments of worth all the time. Every employed person commenting on this board beat out competition for their slot; every person publishing is implicitly competing in the marketplace of ideas for scarce space in journals and other outlets. This competition generally requires us to compare apples and oranges (or maybe Fuji apples and Granny Smiths). Metrics may form one basis for doing so. They need not be the only one. But whether or not they are put into play, make no mistake: these comparisons are being made all the time.
That the metrics are imperfect (paleo-metrics, as one person put it) is not to say they’re useless. One of the benefits of transparency in how they are collected and measured is that these flaws are fairly evident and presumably correctible – we know about the gender gap, and presumably there are other gaps. There is a target and it can be pinned down. Can you say the same about the process by which scholars arrive at their subjective assessments of what constitutes “good” or “impactful” work?
Yes. Of course we should use multiple indicators. And we desperately need more of what you, the TRIPS people, scholars using SNA tools on citations, and others are doing. These metrics are here to stay, and we must develop a better understanding of how they work and what they mean.
This concerns me a bit, though: ‘Can you say the same about the process by which scholars arrive at their subjective assessments of what constitutes “good” or “impactful” work?’ I am totally ready to admit that such approaches introduce all sorts of problems—including subtle race, gender, and other biases. At the same time, the choice isn’t between “subjective” and “objective” or “transparent” and “non-transparent.” Such judgments become transparent by making reasons publicly available. And just because we can develop a quantifiable proxy doesn’t mean that we should conflate that proxy with the underlying ‘thing’ being measured, especially if that ‘thing’ *is* ultimately intersubjective rather than objective in nature.
As I hope we made clear, the bigger concern here is with falling prey to the “we have measure, and that’s better than not having one, so let’s go with it.’ Doing that constitutes an active intervention into the practice of scholarship, with real-world impact on the behavior of scholars. Maybe the academic field we create is, indeed, better than the alternatives. But I see major warning signs when we look at places that have instituted Np and/or Nc as the primary criteria for rewarding scholars and departments.
There are also other consequences. Np criteria put tremendous burden on journals and the peer-review process not only as locations where above-the-bar research gets made ‘public’ (albeit usually understood as ‘public’ to people with institutional access), but as the primary mechanism for allocating academic capital. I’m not sure that journals, and the decisions of a few anonymous referees, can realistically shoulder that burden.
“And just because we can develop a quantifiable proxy doesn’t mean that we should conflate that proxy with the underlying ‘thing’ being measured, especially if that ‘thing’ *is* ultimately intersubjective rather than objective in nature.”
I agree with this statement wholeheartedly: I’ve published on issues of construct validity and measurement in the past, so I take this very seriously. I think a potential next step (that would probably be disastrous for civil discourse on the subject) would be to identify those individuals at different times since PhD who the metrics suggest are very influential and see how that jibes with more subjective, survey-based indicators of influence (i.e., the TRIPS survey).
That would be great. But if we are facing a growing performativity problem, then….
(Oh, and you can’t be held responsible if the field can’t handle the truth….)
The “performativity problem” hypothesis is one that needs to be established, not just asserted, before it is accepted fully. If it was so easy to rig citation counts then everyone would be doing it and it would all just cancel out.
I wasn’t thinking about rigging. More along the lines of “Effective” or “Barnesian” performativity. But that’s just a matter for additional work, not a ‘don’t go there.’
https://www.helsinki.fi/tint/maki/materials/PerformativityEPSAvolume012013.pdf
To your point: I’ve done some analysis that tries to standardize performance relative to cohort (i.e., PhD year) locally smoothed means for the various measures (total cites, h-index and i10, but also highest cited solo work) and the results have considerable face validity. For people with PhDs from 1980 to 1990, the top of the list includes (in alphabetical, rather than rank order) Amitav Acharya, Daniele Archibugi, Andy Bennett, David Lake, Helen Milner, Kathryn Sikkink, Duncan Snidal, and Alec Stone Sweet.
I’m thinking that one of the problems here is similar to the problems you encounter in lots of game theoretic modeling — the fact that you have to assume that there is a ‘default player’ or individual who looks basically the same no matter who is playing. Wondering if the curve looks the same for women — My sense is that a lot of women may be doing their best scholarship as empty nesters and may bloom a bit later as scholars. I’m always struck by how the conferences seem to hollow out as women scholar hit peak childbearing years — lots of women at conferences in their twenties, and then again in their fifties. Often it seems like there are fewer scholars there in their forties and late thirties.
Thanks Dan and PTJ for a good read. I’ve never been a fan of theorizing by analogy, and I don’t think Cullen was attempting to do this in this piece. Moneyball was a nice hook, but probably shouldn’t lead to the conclusion that political science = baseball.
The issue at stake, as far as I understand it, is how to observe productivity. Do we need to? As a department chair/dean/hiring committee, the answer is a clear yes.
I think Cullen’s post, your response, some of the comments help us all think about how we might do so. Clearly an H Index can inflate Huntington and deflate scholars for a variety of reasons. But to suggest that we can not observe productivity and that metrics are useless is not what I (hope?) think you’re saying.
In most cases, I think these metrics provide a way to think about productivity that is open and worthy of debate and revision. Coupled with more subjective assessments, I think these can be truly powerful tools (starting to sound Bayesian). Relying on whether a scholar is productive based solely on opaque subjective assessments or because they belong to the right club or received their PhD from the right place, strikes me as (the worst?) a worse way of thinking about productivity.
In sum, the H index or any metric needs to be matched to a concept. Assuming the concept is productivity than the arguments should be over how best to do so and how best to combine with other ways to observe the phenomenon to generate a more complete picture.
Just to be clear, the target isn’t what Cullen’s doing. The analogy provides a springboard for related, but separable, issues.
Joe, why do we need to observe productivity? Can’t we observe other things, like “being intellectually interesting and engaged”? You know, stuff that is probably more closely related to our day jobs of being good teachers for the students paying massive tuition bills for the privilege of sitting in our classrooms?
So, you don’t think “being intellectually interesting and engaged” correlates with GS citations? I’m not exactly sure why I keep citing all these disengaged, uninteresting scholars, then! I’m not saying they are perfectly correlated but let’s not just assume the opposite.
Hi PTJ and Dan, Interesting
discussion! A few points: (1) I don’t think anyone would argue that
“winning” higher education is based solely on GS citations. (2) However,
to answer your question “Does a department composed of
scholars with high h-index numbers ‘win’ higher education?”, probably
not. But, a department composed solely of
scholars with low h-index numbers definitely isn’t “winning” much in terms of
productivity and, I would venture, in terms of research. And (3), could you provide me with a few
examples of scholars that are “losing” the h-index/GS citation “battle” but are
still contributing to our IR knowledge? I am betting they are still “winning”
in other areas that could also be quantified Moneyball-style (like association-level
awards for books and articles, counter-offers, invited talks, grant monies etc). I’m not arguing that the Scholar-Only-Known-By-Non-Moneyball-Methods doesn’t exist; I just can’t think of any myself.
I also wonder about advantages that might accrue over time, in an iterative fashion. I.E. Publish a couple of articles that have a lot of impact in top journals, get awarded a big prestigious fellowship which funds you to do more of the same sort of work, etc. I think the recent dustup about the fellow from California with the manufactured data suggests that often the people who are doing the hiring, etc. might not actually be reading all or analyzing all the scholarship as much as using it as a proxy for something else like reputation, impact, evidence of future productivity, then piling on if something “seems” solid or significant, even if it i isn’t.
The Lacour fiasco is due to metrics-based analysis? His malfeasance was so deliberate and layered that his own CO-AUTHOR, one of the discipline’s leading scholars, didn’t catch it. This is a bridge too far for me. As long as there is any means by which we assign differential rewards (economic, social and professional) to work, these types of things will happen.
Perhaps their point was not that defining winning by GS citations was wrong but that seeing academia as something that you can win is wrong. Like, say, breakfast. A might eat more lucky charms than B but that doesn’t mean that A wins. Winning is just not something that happens to breakfast.
I think winning breakfast is a lot easier than winning academia, personally ;-)
I wonder what the authors would think about the ‘metrics’ that you get on academia.edu which tell you who has downloaded your article and even generates a map for you of all of the countries where your work is being read. It also tells you the query they used to find your work and the city where the query originated (which is kind of cool if you write about intell, since sometimes you can figure out it’s a city that has a military academy, etc.) I ask because there are ‘ads’ on the site where individuals note that they are including these maps and lists of queries in their tenure files as evidence that their scholarship is getting out there.
Personally, I’ve been wondering about the economics of the thing — My sense is that people search academia.edu when they can’t afford to subscribe to the journal you might have published some version of the piece in. I wonder if overall your work gets cited less or more depending on other factors like how expensive the database is that your work appeared in and how many universities in the US and abroad can afford to subscribe to it.
Comments on the the conceptual and practical issues. First: Yes, even “wrong” arguments like Clash of Civilizations are an important part of “producing knowledge.” After all, the vast majority of people on this planet are not constructivists. They believe deeply that Huntington’s argument is obvious. Constructivism asks a lot of people, particularly those who assume,
unknowingly, a primordialist understanding of identity. It’s hard to
teach. Most of us teach at places where our students share those primordialist assumptions, at least at the start of the semester. We need such readable examples to use in undergraduate classrooms – they’re useful foils. The fact that thousands have converged on it as a focal point for debate is instructive (can I learn to write like that please?), and more importantly it pushed scholarship on identity forward in useful ways. (And of course one can’t deny Huntington was a monstrously influential scholar, even if he had some misses as well as hits. Nobody’s perfect.)
On the practical issue: the real problem is that we still lack accurate measures of impact, for many of us. Many of the comments below, as well as the OP, wonder about book citations. Please see my two articles in PS: BOTH articles AND books are undercounted because Google Scholar does not accurately count citations in books. This does not mean that there’s no “truth” to GS: a highly-cited article in GS will remain highly cited once you account the # of cites it has obtained in books. And a poorly-cited article will remain poorly-cited after doing the same. So OK, GS is a decent proxy for “impact” (I do not say “knowledge production” because I don’t think that’s what we do) *for people who write articles*. But it is not a good proxy for impact for people who write books, especially for younger scholars, since their cite counts will be deflated when the clock expires, compared to someone who writes articles.
I know that political scientists tend to completely ignore PS, but once in a while there’s a semi-informative little article in there…on citation counts, at least…
“But it is not a good proxy for impact for people who write books, especially for younger scholars…”
Can you elaborate on this please? Do you mean just that it takes a long to write books and then a long time for them to appear, therefore they will be cited less? Or do you mean that there is a counting bias against books in the metrics?
So I realize that I am late to the discussion but two points:
1) Win Shares? Really? I love Bill James and I have read that book from cover to cover and back again but that is so 2005. I would like to introduce Dan and Patrick to Wins Above Replacement (WAR). You even have your choice of two different yet legitimate models!
2) Should I be the guy who says that much of the debate below is the rationalist/constructivist, dualist/monist, (neo)positivist/post-positivist debate replayed in the realm of citation scores? Right down to the level where I keep feeling like the side that I disagree with is missing the point.
Eh. I’m not convinced. Academic does have a “goal”. It is to produce knowledge that is both insightful and useful, and in that, we are all on the same team, working toward the same goal. A citation means that other people have read your work and found it important in developing their own work–“standing on the shoulders of giants.” It’s akin to a “assist” in basketball; we are just producing an endless stream of assists. So, citations do matter. They should be taken as a piece of information–among many, and not exclusively–in evaluating colleagues for hiring, tenure, and promotion. And don’t lie, sir, you check your own citation counts too. :-)
I hesitate to mention this, but…the “h” index may (or may not) be a good measure of *research productivity* (or expected research productivity). But I have seen nothing that suggests any particular relationship between the “h” index and teaching quality. And, last time I checked, that was part of the job (at least it was part of mine before I retired).
Some reflections on this discussion:
1. I’m guessing one could sort us into two groups – those that view metrics as more useful than harmful and those that view them as more harmful than useful – with 90% accuracy with one simple question: “Do you do quantitative empirical work?”
2. If the dominant method of conferring status and stature in the discipline were pulling names from a large burlap sack, there would be some subset of us (the “chosen ones”) using considerable brainpower defending the wisdom of the sack. That is, we should expect that any evaluative criterion that has distributive consequences, real or implied, would have its defenders. This is as true of the caricature “metrics are all that matter” as it was/is of the old boy’s network, and true independent of any intellectual merit a given system might have.
3. No, academia shouldn’t be like baseball. But it also shouldn’t be like wine tasting or movie reviewing, where evaluations are notoriously idiosyncratic and unstable over time. In circumstances where evaluations are highly personal and taste matters, I’m usually partial to wisdom of crowds. This doesn’t mean an individual scholar should abdicate their responsibility to use their judgment, but it does mean individual scholars should be open to the idea they are missing something at least some of the time.
4. Yes, some subfields or issue areas within IR (or any discipline) will be more heavily traveled and highly cited than others. But that doesn’t mean the h-index or another metric is without value: it means we can decide that we value different approaches and subjects and then, as need be, compare apples to apples. Feminist IR is not generally as highly as quant conflict stuff. Fine. But when comparing feminist IR scholars to feminist IR scholars, you can’t tell me the person with the h-index of 20 and the person with the h-index of 5 have had similar impacts on the subfield.
The h-index is a good predictor of future Np and Nc performance (see Cullen’s post and the paper I link to). That’s not the same thing as saying that h-index measures impact.
The sport-academia analogy has some very very rich company:
‘The workplace should be infused with transparency and precision about who is really achieving and who is not. Within Amazon, ideal employees are often described as “athletes” with endurance, speed (No. 8: “bias for action”), performance that can be measured and an ability to defy limits (No. 7: “think big”).’
https://www.nytimes.com/2015/08/16/technology/inside-amazon-wrestling-big-ideas-in-a-bruising-workplace.html?smid=tw-share&_r=0
Overall, the picture painted in the article of how Jeff Bezos’ ‘overarching confidence in metrics’ contributed to a particularly relentless and heartless work environment might just be the specter at our current feast of productivity metrics (some will say slippery slope–maybe, so long as we admit the slope).
I like this discussion a lot, but I believe this is a discussion one cannot win or loose: most arguments posted here have some truth in it, but none is convincing to push forward GS or to ditch it. One can just put some nuance to people’s academic output. It is up to your peers to decide what is quality work with all the methodological problems (read in PTJ’s terms) that come with this. And we all know, this is very very difficult to judge, we always do it by proxy.
Aside from all the other arguments, I know the GS works quite well for article counts, but from the moment you go to grey literature like reports, working papers or policy papers, it does not work anymore.
With a closer look at the top of the field, it supports the idea that the most-cited authors are Ivy League professors (what a suprise), but gives some credit to “Europeans” like Archibugi, Zürn, Gleditsch and Gleditsch, Hurrell, Rittberger, Bierman, et. al. which score very high but are not the typical people to appear in American lists of who’s who in IR. And this becomes every more outspoken if you go to the list of scholars with GS scores between 2000 and 5000. In the same vein, but probably more problematic for some, is that some people with a Ph.D (I still have to earn mine) have a very low score and still have a fancy tenured place at a nice (US) university. Good for them, but maybe this indicates that sometimes search committees pick the wrong person?
So, search commitees or universities can also use GS as a headhunting tool as the unvisable become a bit more visible through systems like this. You need to use new tools to discover what you do not know, instead of searching for the confirmation of things you already know…so Cullen Hendrix’ post openend up the debate more in my reading than PTJ and DN reply (to close it?). I agree with their critiques but still, let’s try to use a tool to find things you cannot find in a normal paper CV.
In this light, I find this discussion of metrics realy interesting when one wants to dig deeper into a person’s CV. For instance some people decide to publish their work in non-indexed journals. Some of these, can get very big citations. For me, this becomes than a publication which has the same appeal as an indexed journal article.
Nonetheless, it would be great that all scholars would have a GS that is publicly accesable and using the same keywords/labels, like for instance ‘international relations’. https://scholar.google.be/citations?view_op=search_authors&hl=en&mauthors=label:international_relations
And that scholars clean up their GS when it includes publications that are not theirs, double counts, etc.
But again, very interesting discussion with many interesting thoughts in the comments’ section.